ML | LogisticRegression Algorithm.
Logistic regression is the most famous machine learning algorithm after linear regression. In a lot of ways, linear regression and logistic regression are similar. But, the biggest difference lies in what they are used for. Linear regression algorithms are used to predict/forecast values but logistic regression is used for classification tasks.
There are many classification tasks done routinely by people. For example, classifying whether an email is a spam or not, classifying whether a tumour is malignant or benign, classifying whether a website is fraudulent or not, etc. These are typical examples where machine learning algorithms can make our lives a lot easier. A really simple, rudimental and useful algorithm for classification is the logistic regression algorithm. Now, let’s take a deeper look into logistic regression.
Sigmoid Function (Logistic Function)
Logistic regression algorithm also uses a linear equation with independent predictors to predict a value. The predicted value can be anywhere between negative infinity to positive infinity. We need the output of the algorithm to be class variable, i.e 0-no, 1-yes. Therefore, we are squashing the output of the linear equation into a range of [0,1]. To squash the predicted value between 0 and 1, we use the sigmoid function.
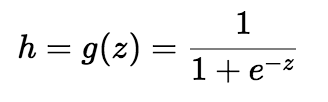
We take the output(z) of the linear equation and give to the function g(x) which returns a squashed value h, the value h will lie in the range of 0 to 1. To understand how sigmoid function squashes the values within the range, let’s visualize the graph of the sigmoid function.

As you can see from the graph, the sigmoid function becomes asymptote to y=1 for positive values of x and becomes asymptote to y=0 for negative
Cost Function
Since we are trying to predict class values, we cannot use the same cost function used in linear regression algorithm. Therefore, we use a logarithmic loss function to calculate the cost for misclassifying.

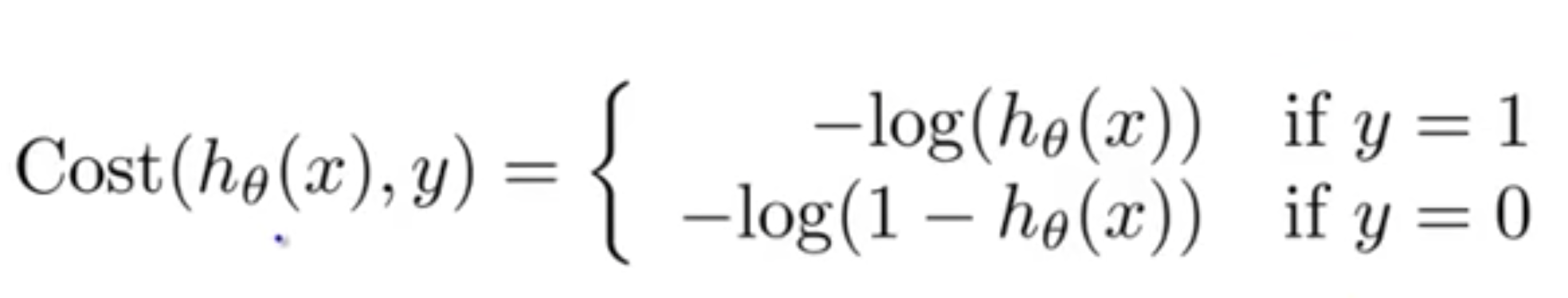
The above cost function can be rewritten as below since calculating gradients from the above equation is difficult.



Here h teta (x) is our predictions.
Code
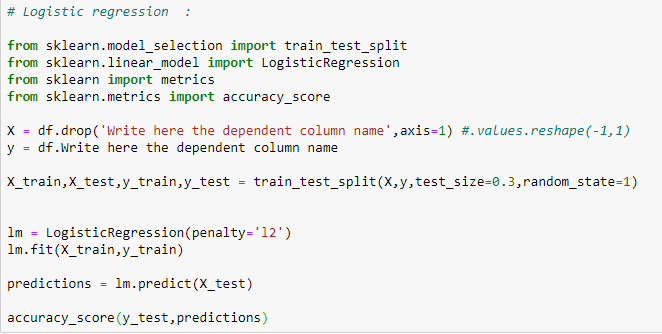
In above code i have assumed that the data is stored in the variable df
No comments:
Post a Comment